class: center, middle, title-slide, inverse, no-scribble layout: false <audio controls> <source src="media/rush_subdivisions.mp3" type="audio/mpeg"> <source src="media/rush_subdivisions.ogg" type="audio/ogg"/> </audio> # Contrast coding ## Professor Andy Field <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/twitter_60.png"> <span style="line-height:40px;">@profandyfield</span> </div> <div> <img style="vertical-align:middle; width:60px" src="media/youtube.png"> <span style="line-height:40px;">www.youtube.com/user/ProfAndyField/</span> </div> <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/ds_com_fav.png"> <span style="line-height:40px;">www.discoveringstatistics.com</span> </div> <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/milton_grey_fav.png"> <span style="line-height:40px;">www.milton-the-cat.rocks</span> </div> <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/discovr_fav.png"> <span style="line-height:40px;">www.discovr.rocks</span> </div> ??? Music: Rush Subdivisions h or ?: Toggle the help window j: Jump to next slide k: Jump to previous slide b: Toggle blackout mode m: Toggle mirrored mode. p: Toggle PresenterMode f: Toggle Fullscreen t: Reset presentation timer <number> + <Return>: Jump to slide <number> c: Create a clone presentation on a new window --- class: center class: center  ??? We've seen this map of the process of fitting models before --- class: center  ??? Today we focus back on the model itself to look at the form of the model we're fitting. The faded stuff still applies though - we'll look at bias, robust models, and of course samples and estimation and so on. But they are the same as for other models, what is different is the form of the model we're fitting. --- # Learning outcomes * Explain the different ways to break down categorical predictors in a linear model + Planned contrasts/comparisons) + Choosing contrasts + Contrast coding -- * *Post hoc* tests -- * Polynomial contrasts (trend analysis) --- # Contrast coding * The *F*-statistic tests the overall fit of the model + i.e. It is a general test of model fits/whether group means significantly differ -- * Model parameters tells us about specific differences between means + Dummy coding compares each category to a baseline -- * What do we do when dummy coding does not reflect our *a priori* hypotheses? --- # Options for breaking down categorical predictors * Orthogonal contrasts (contrast coding) + Hypothesis driven + Planned *a priori* + Control Type I error rate -- * *Post hoc* tests + Not planned (not hypothesis driven) + Compare all pairs of means + Multiple *t*-tests adjusted for the number of tests -- * Trend analysis + Useful only for ordered means --- background-image: none background-color: #000000 class: no-scribble <video width="100%" height="100%" controls id="my_video"> <source src="media/milton_insert_puppies.mp4" type="video/mp4"> </video> --- # A puppy-tastic example * A puppy therapy RCT in which we randomized people into three groups: + A control group + 15 minutes of puppy therapy + 30 minutes of puppy contact. -- * The outcome is happiness (0 = unhappy) to 10 (happy).  -- * Predictions: + Any form of puppy therapy should be better than the control (i.e. higher happiness scores) + A dose-response hypothesis that as exposure time increases (from 15 to 30 minutes) happiness will increase too. --- background-image: url("media/milton_20190724_155300.JPG") background-size: cover # The data .pull-left[.whitebox[ <div id="mabmadequd" style="padding-left:0px;padding-right:0px;padding-top:10px;padding-bottom:10px;overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>#mabmadequd table { font-family: system-ui, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; } #mabmadequd thead, #mabmadequd tbody, #mabmadequd tfoot, #mabmadequd tr, #mabmadequd td, #mabmadequd th { border-style: none; } #mabmadequd p { margin: 0; padding: 0; } #mabmadequd .gt_table { display: table; border-collapse: collapse; line-height: normal; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #mabmadequd .gt_caption { padding-top: 4px; padding-bottom: 4px; } #mabmadequd .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #mabmadequd .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 3px; padding-bottom: 5px; padding-left: 5px; padding-right: 5px; border-top-color: #FFFFFF; border-top-width: 0; } #mabmadequd .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #mabmadequd .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #mabmadequd .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #mabmadequd .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #mabmadequd .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #mabmadequd .gt_column_spanner_outer:first-child { padding-left: 0; } #mabmadequd .gt_column_spanner_outer:last-child { padding-right: 0; } #mabmadequd .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #mabmadequd .gt_spanner_row { border-bottom-style: hidden; } #mabmadequd .gt_group_heading { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; text-align: left; } #mabmadequd .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #mabmadequd .gt_from_md > :first-child { margin-top: 0; } #mabmadequd .gt_from_md > :last-child { margin-bottom: 0; } #mabmadequd .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #mabmadequd .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; } #mabmadequd .gt_stub_row_group { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 5px; padding-right: 5px; vertical-align: top; } #mabmadequd .gt_row_group_first td { border-top-width: 2px; } #mabmadequd .gt_row_group_first th { border-top-width: 2px; } #mabmadequd .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #mabmadequd .gt_first_summary_row { border-top-style: solid; border-top-color: #D3D3D3; } #mabmadequd .gt_first_summary_row.thick { border-top-width: 2px; } #mabmadequd .gt_last_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #mabmadequd .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #mabmadequd .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #mabmadequd .gt_last_grand_summary_row_top { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-bottom-style: double; border-bottom-width: 6px; border-bottom-color: #D3D3D3; } #mabmadequd .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #mabmadequd .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #mabmadequd .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #mabmadequd .gt_footnote { margin: 0px; font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #mabmadequd .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #mabmadequd .gt_sourcenote { font-size: 90%; padding-top: 4px; padding-bottom: 4px; padding-left: 5px; padding-right: 5px; } #mabmadequd .gt_left { text-align: left; } #mabmadequd .gt_center { text-align: center; } #mabmadequd .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #mabmadequd .gt_font_normal { font-weight: normal; } #mabmadequd .gt_font_bold { font-weight: bold; } #mabmadequd .gt_font_italic { font-style: italic; } #mabmadequd .gt_super { font-size: 65%; } #mabmadequd .gt_footnote_marks { font-size: 75%; vertical-align: 0.4em; position: initial; } #mabmadequd .gt_asterisk { font-size: 100%; vertical-align: 0; } #mabmadequd .gt_indent_1 { text-indent: 5px; } #mabmadequd .gt_indent_2 { text-indent: 10px; } #mabmadequd .gt_indent_3 { text-indent: 15px; } #mabmadequd .gt_indent_4 { text-indent: 20px; } #mabmadequd .gt_indent_5 { text-indent: 25px; } </style> <table class="gt_table" data-quarto-disable-processing="false" data-quarto-bootstrap="false"> <thead> <tr class="gt_col_headings"> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1" scope="col" id=""></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="No puppies">No puppies</th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="15 mins">15 mins</th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1" scope="col" id="30 mins">30 mins</th> </tr> </thead> <tbody class="gt_table_body"> <tr><th id="stub_1_1" scope="row" class="gt_row gt_left gt_stub"></th> <td headers="stub_1_1 No puppies" class="gt_row gt_center">3</td> <td headers="stub_1_1 15 mins" class="gt_row gt_center">5</td> <td headers="stub_1_1 30 mins" class="gt_row gt_center">7</td></tr> <tr><th id="stub_1_2" scope="row" class="gt_row gt_left gt_stub"></th> <td headers="stub_1_2 No puppies" class="gt_row gt_center">2</td> <td headers="stub_1_2 15 mins" class="gt_row gt_center">2</td> <td headers="stub_1_2 30 mins" class="gt_row gt_center">4</td></tr> <tr><th id="stub_1_3" scope="row" class="gt_row gt_left gt_stub"></th> <td headers="stub_1_3 No puppies" class="gt_row gt_center">1</td> <td headers="stub_1_3 15 mins" class="gt_row gt_center">4</td> <td headers="stub_1_3 30 mins" class="gt_row gt_center">5</td></tr> <tr><th id="stub_1_4" scope="row" class="gt_row gt_left gt_stub"></th> <td headers="stub_1_4 No puppies" class="gt_row gt_center">1</td> <td headers="stub_1_4 15 mins" class="gt_row gt_center">2</td> <td headers="stub_1_4 30 mins" class="gt_row gt_center">3</td></tr> <tr><th id="stub_1_5" scope="row" class="gt_row gt_left gt_stub"></th> <td headers="stub_1_5 No puppies" class="gt_row gt_center">4</td> <td headers="stub_1_5 15 mins" class="gt_row gt_center">3</td> <td headers="stub_1_5 30 mins" class="gt_row gt_center">6</td></tr> <tr><th id="grand_summary_stub_1" scope="row" class="gt_row gt_left gt_stub gt_grand_summary_row gt_first_grand_summary_row">Mean</th> <td headers="grand_summary_stub_1 No puppies" class="gt_row gt_center gt_grand_summary_row gt_first_grand_summary_row" style="background-color: rgba(202,62,52,0.8); color: #E8EAE5; font-weight: bold;">2.20</td> <td headers="grand_summary_stub_1 15 mins" class="gt_row gt_center gt_grand_summary_row gt_first_grand_summary_row" style="background-color: rgba(202,62,52,0.8); color: #E8EAE5; font-weight: bold;">3.20</td> <td headers="grand_summary_stub_1 30 mins" class="gt_row gt_center gt_grand_summary_row gt_first_grand_summary_row" style="background-color: rgba(202,62,52,0.8); color: #E8EAE5; font-weight: bold;">5.00</td></tr> <tr><th id="grand_summary_stub_2" scope="row" class="gt_row gt_left gt_stub gt_grand_summary_row">Variance (<i>s</i><sup>2</sup>)</th> <td headers="grand_summary_stub_2 No puppies" class="gt_row gt_center gt_grand_summary_row">1.70</td> <td headers="grand_summary_stub_2 15 mins" class="gt_row gt_center gt_grand_summary_row">1.70</td> <td headers="grand_summary_stub_2 30 mins" class="gt_row gt_center gt_grand_summary_row">2.50</td></tr> <tr><th id="grand_summary_stub_3" scope="row" class="gt_row gt_left gt_stub gt_grand_summary_row gt_last_summary_row">Standard deviation (<i>s</i>)</th> <td headers="grand_summary_stub_3 No puppies" class="gt_row gt_center gt_grand_summary_row gt_last_summary_row">1.30</td> <td headers="grand_summary_stub_3 15 mins" class="gt_row gt_center gt_grand_summary_row gt_last_summary_row">1.30</td> <td headers="grand_summary_stub_3 30 mins" class="gt_row gt_center gt_grand_summary_row gt_last_summary_row">1.58</td></tr> </tbody> </table> </div> ]] <br> -- .pull-right[ .whitebox[.center[.eq_lrge[ `\(\text{Overall mean (} \bar{X}_\text{grand}\text{)} = 3.467\)` ]]]] --- background-image: url("media/milton_20190801_160443.JPG") background-size: cover # The general linear model ## Dummy coding -- <table> <thead> <tr> <th style="text-align:left;"> Therapy group </th> <th style="text-align:center;"> Long (30 mins vs. no puppies) </th> <th style="text-align:center;"> Short 1 (15 mins vs. no puppies) </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> No Puppies </td> <td style="text-align:center;background-color: white !important;"> 0 </td> <td style="text-align:center;background-color: white !important;"> 0 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;"> 15 mins </td> <td style="text-align:center;background-color: white !important;"> 0 </td> <td style="text-align:center;background-color: white !important;"> 1 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;"> 30 mins </td> <td style="text-align:center;background-color: white !important;"> 1 </td> <td style="text-align:center;background-color: white !important;"> 0 </td> </tr> </tbody> </table> <br> -- .whitebox[.center[.eq_lrge[ $$ `\begin{aligned} \text{Happiness}_i &= \hat{b}_0 + \hat{b}_1\text{Long}_i + \hat{b}_2\text{Short}_i + e_i \end{aligned}` $$ ]]] --- class: center # The 'dummy' model 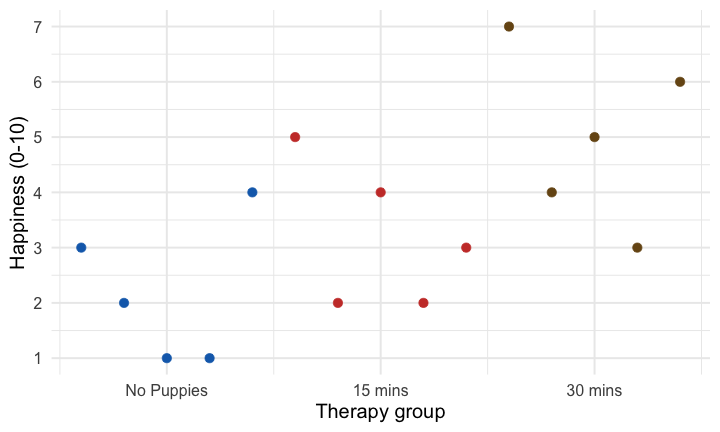<!-- --> --- class: center # The 'dummy' model 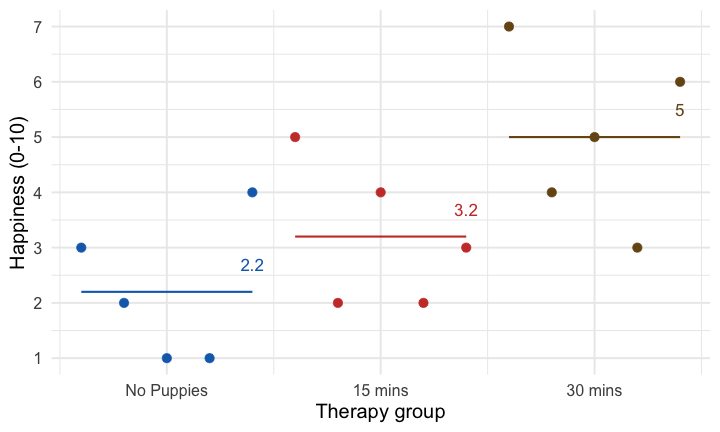<!-- --> --- class: center # The 'dummy' model <!-- --> --- # The model .ong[.center[.eq_lrge[ $$ `\begin{aligned} \hat{\text{Happiness}}_i &= \hat{b}_0 + \hat{b}_1\text{Long}_i + \hat{b}_2\text{Short}_i \end{aligned}` $$ ]]] .pull-left[ <!-- --> ] -- .pull-right[ .ong[.eq_lrge[ $$ `\begin{aligned} \hat{b}_0 &= \bar{X}_\text{No puppies} = 2.2 \\ \hat{b}_1 &= 5.0-2.2 = 2.8 \\ \hat{b}_2 &= 3.2-2.2 = 1.0 \end{aligned}` $$ ]] ] --- # Model fit: *F*-statistic ```r puppy_lm <- lm(happiness ~ dose, data = puppy_tib) broom::glance(puppy_lm) ``` .center[ <table> <thead> <tr> <th style="text-align:right;"> r.squared </th> <th style="text-align:right;"> adj.r.squared </th> <th style="text-align:right;"> sigma </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> <th style="text-align:right;"> df </th> <th style="text-align:right;"> logLik </th> <th style="text-align:right;"> AIC </th> <th style="text-align:right;"> BIC </th> <th style="text-align:right;"> deviance </th> <th style="text-align:right;"> df.residual </th> <th style="text-align:right;"> nobs </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;background-color: yellow !important;"> 0.46 </td> <td style="text-align:right;background-color: yellow !important;"> 0.37 </td> <td style="text-align:right;"> 1.4 </td> <td style="text-align:right;background-color: yellow !important;"> 5.12 </td> <td style="text-align:right;"> 0.02 </td> <td style="text-align:right;background-color: yellow !important;"> 2 </td> <td style="text-align:right;"> -24.68 </td> <td style="text-align:right;"> 57.37 </td> <td style="text-align:right;"> 60.2 </td> <td style="text-align:right;"> 23.6 </td> <td style="text-align:right;background-color: yellow !important;"> 12 </td> <td style="text-align:right;"> 15 </td> </tr> </tbody> </table> ] # Parameter estimates ```r broom::tidy(puppy_lm, conf.int = TRUE) ``` .center[ <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> <th style="text-align:right;"> conf.low </th> <th style="text-align:right;"> conf.high </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;"> 2.2 </td> <td style="text-align:right;"> 0.63 </td> <td style="text-align:right;"> 3.51 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 0.83 </td> <td style="text-align:right;"> 3.57 </td> </tr> <tr> <td style="text-align:left;"> dose15 mins </td> <td style="text-align:right;background-color: yellow !important;"> 1.0 </td> <td style="text-align:right;"> 0.89 </td> <td style="text-align:right;"> 1.13 </td> <td style="text-align:right;"> 0.28 </td> <td style="text-align:right;"> -0.93 </td> <td style="text-align:right;"> 2.93 </td> </tr> <tr> <td style="text-align:left;"> dose30 mins </td> <td style="text-align:right;background-color: yellow !important;"> 2.8 </td> <td style="text-align:right;"> 0.89 </td> <td style="text-align:right;"> 3.16 </td> <td style="text-align:right;"> 0.01 </td> <td style="text-align:right;"> 0.87 </td> <td style="text-align:right;"> 4.73 </td> </tr> </tbody> </table> ] --- # Planned contrasts * The variability explained by the model, SS<sub>M</sub> is due to participants being assigned to different groups + This variability sometimes represents an experimental manipulation -- * This variability (SS<sub>M</sub>) can be broken down further to test specific hypotheses about which groups might differ -- * We break down the variance according to hypotheses made *a priori* (before the experiment) -- * It’s like cutting up a cake (yum yum!) --- background-image: none background-color: #000000 class: no-scribble <video width="100%" height="100%" controls id="my_video"> <source src="media/partitioning_chocolate_silent.mp4" type="video/mp4"> </video> --- # The cake analogy again  --   --   --   --- # Choosing contrasts * Independent + To control Type I error rates contrasts must be independent (they must test unique hypotheses) + If a group is singled out in a contrast, then that group should not be used in any subsequent contrasts -- * Only 2 Chunks + Each contrast should compare only 2 chunks of variation (why?) -- * *K*-1 + You should always end up with one less contrast than the number of groups --- # How do I choose contrasts? .tip[ ## <svg style="height:1.5em; top:.04em; position: relative; fill: #2C5577;" viewBox="0 0 640 512"><path d="M512,176a16,16,0,1,0-16-16A15.9908,15.9908,0,0,0,512,176ZM576,32.72461V32l-.46094.3457C548.81445,12.30469,515.97461,0,480,0s-68.81445,12.30469-95.53906,32.3457L384,32v.72461C345.35156,61.93164,320,107.82422,320,160c0,.38086.10938.73242.11133,1.11328A272.01015,272.01015,0,0,0,96,304.26562V176A80.08413,80.08413,0,0,0,16,96a16,16,0,0,0,0,32,48.05249,48.05249,0,0,1,48,48V432a80.08413,80.08413,0,0,0,80,80H352a32.03165,32.03165,0,0,0,32-32,64.0956,64.0956,0,0,0-57.375-63.65625L416,376.625V480a32.03165,32.03165,0,0,0,32,32h32a32.03165,32.03165,0,0,0,32-32V316.77539A160.036,160.036,0,0,0,640,160C640,107.82422,614.64844,61.93164,576,32.72461ZM480,32a126.94015,126.94015,0,0,1,68.78906,20.4082L512,80H448L411.21094,52.4082A126.94015,126.94015,0,0,1,480,32Zm64,64v64a64,64,0,0,1-128,0V96l21.334,16h85.332ZM480,480H448V351.99609A15.99929,15.99929,0,0,0,425.5,337.377L303.1875,391.75a100.1169,100.1169,0,0,0-67.25-84.89062,7.96929,7.96929,0,0,0-10.09375,5.76562l-3.875,15.5625a8.16346,8.16346,0,0,0,5.375,9.5625C252,346.875,272,375.625,272,401.90625V448h48a32.03165,32.03165,0,0,1,32,32H144c-26.94531,0-48.13086-22.27344-47.99609-49.21875.63671-127.52734,101.31054-231.53516,227.36914-238.14063A160.02931,160.02931,0,0,0,480,320Zm0-192A128.14414,128.14414,0,0,1,352,160c0-32.16992,12.334-61.25391,32-83.76367V160a96,96,0,0,0,192,0V76.23633C595.666,98.74609,608,127.83008,608,160A128.14414,128.14414,0,0,1,480,288ZM432,160a16,16,0,1,0,16-16A15.9908,15.9908,0,0,0,432,160ZM162.94531,68.76953l39.71094,16.56055,16.5625,39.71094a5.32345,5.32345,0,0,0,9.53906,0l16.5586-39.71094,39.71484-16.56055a5.336,5.336,0,0,0,0-9.541l-39.71484-16.5586L228.75781,2.957a5.325,5.325,0,0,0-9.53906,0l-16.5625,39.71289-39.71094,16.5586a5.336,5.336,0,0,0,0,9.541Z"/></svg> Big Hint: * Most experimental designs typically have one or more control groups * The logic of control groups means that we expect scores within them to differ from those in the groups we've manipulated * The first contrast will usually compare any control conditions (chunk 1) with any experimental ones (chunk 2) ] ??? In our puppy therapy example, what hypotheses might we have? Think about that during interlude --- background-image: none background-color: #000000 class: no-scribble <video width="100%" height="100%" controls id="my_video"> <source src="media/milton_slideshow.mp4" type="video/mp4"> </video> --- # Hypotheses ## Hypothesis 1: * People who have puppy therapy will be happier (have have higher happiness scores) than those who don’t * Control `\(\ne\)` (15 mins, 30 mins) -- ## Hypothesis 2: * People receiving a high dose of puppy therapy (30 mins) will be happier than those receiving a low dose (15 mins) * 15 mins `\(\ne\)` 30 mins --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- # Coding planned contrasts * Rule 1 + Groups coded with positive weights compared to groups coded with negative weights -- * Rule 2 + The sum of weights for a comparison should be zero -- * Rule 3 + If a group is not involved in a comparison, assign it a weight of zero -- * Rule 4 + For a given contrast, the **initial weight** assigned to the group(s) in one chunk of variation should be equal to the number of groups in the opposite chunk of variation -- * Rule 5 + To get the **final weight**, divide the initial weights by the number of groups with non-zero weights --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- class: center  --- background-image: none background-color: #000000 class: no-scribble <video width="100%" height="100%" controls id="my_video"> <source src="media/lazinc_durt_your_time_will_come.mp4" type="video/mp4"> </video> --- background-image: url("media/milton_20190623_191707.jpg") background-size: cover # .gry[What the coding does] -- ## .gry[Dummy coding] .center[ <table> <thead> <tr> <th style="text-align:left;"> Therapy group </th> <th style="text-align:center;"> Long (30 mins vs. no puppies) </th> <th style="text-align:center;"> Short 1 (15 mins vs. no puppies) </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> No Puppies </td> <td style="text-align:center;background-color: white !important;"> 0 </td> <td style="text-align:center;background-color: white !important;"> 0 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;"> 15 mins </td> <td style="text-align:center;background-color: white !important;"> 0 </td> <td style="text-align:center;background-color: white !important;"> 1 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;"> 30 mins </td> <td style="text-align:center;background-color: white !important;"> 1 </td> <td style="text-align:center;background-color: white !important;"> 0 </td> </tr> </tbody> </table> ] <br> -- ## .gry[Contrast coding] .center[ <table> <thead> <tr> <th style="text-align:left;"> Therapy group </th> <th style="text-align:center;"> Contrast 1 (Puppies vs. no puppies) </th> <th style="text-align:center;"> Contrast 2 (15 mins vs. 30 mins) </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> No Puppies </td> <td style="text-align:center;background-color: white !important;"> -2/3 </td> <td style="text-align:center;background-color: white !important;"> 0 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;"> 15 mins </td> <td style="text-align:center;background-color: white !important;"> 1/3 </td> <td style="text-align:center;background-color: white !important;"> -1/2 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;"> 30 mins </td> <td style="text-align:center;background-color: white !important;"> 1/3 </td> <td style="text-align:center;background-color: white !important;"> 1/2 </td> </tr> </tbody> </table> ] --- background-image: url("media/milton_dawlish_beach_2018.jpg") background-size: cover # The 'dummy' model .whitebox[.eq_lrge[.ong[ $$ `\begin{aligned} \hat{\text{Happiness}}_i &= \hat{b}_0 + \hat{b}_1\text{Long}_i + \hat{b}_2\text{Short}_i \\ \hat{\text{Happiness}}_i &= \hat{b}_0 + \hat{b}_1\text{30 vs. control}_i + \hat{b}_2\text{15 vs.control}_i\\ \end{aligned}` $$ ]]] <br> -- # The 'contrast' model .whitebox[.eq_lrge[.ong[ $$ `\begin{aligned} \hat{\text{Happiness}}_i &= \hat{b}_0 + \hat{b}_1\text{Contrast 1}_i + \hat{b}_2\text{Contrast 2}_i \\ \hat{\text{Happiness}}_i &= \hat{b}_0 + \hat{b}_1\text{Therapy vs. control}_i + \hat{b}_2\text{15 vs. 30 mins}_i \\ \end{aligned}` $$ ]]] --- class: center # The 'dummy' model <!-- --> --- class: center # The 'dummy' model <!-- --> --- class: center # The 'dummy' model 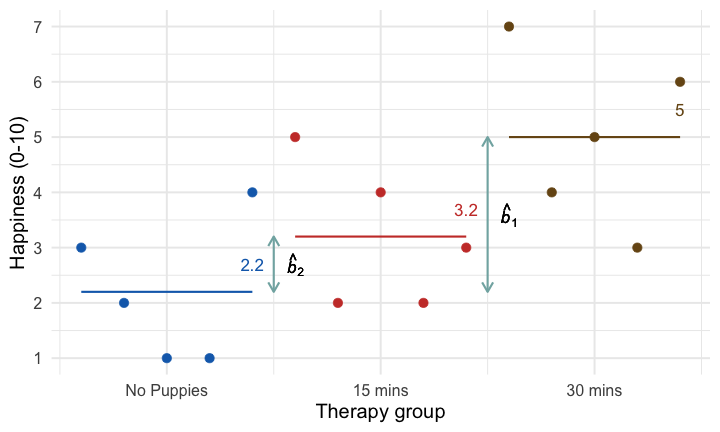<!-- --> --- class: center # The contrast model 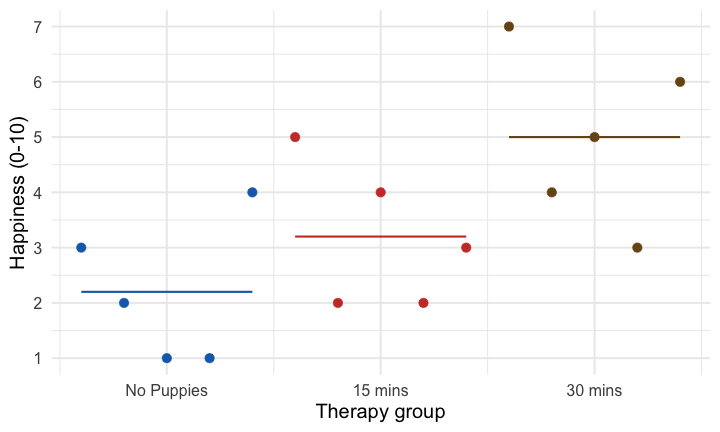<!-- --> --- class: center # The contrast model: Contrast 1 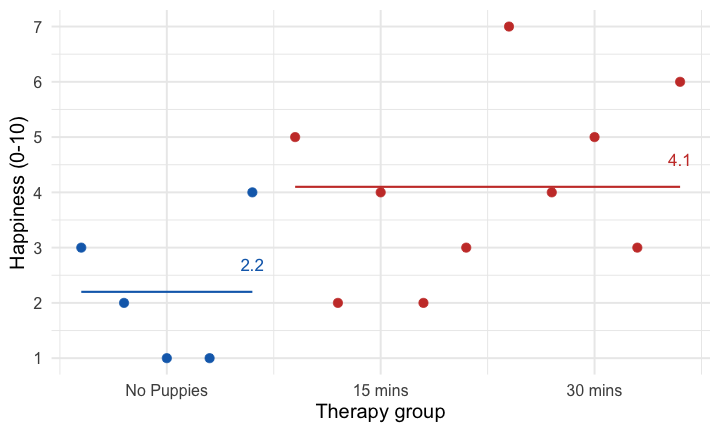<!-- --> --- class: center # The contrast model: Contrast 1 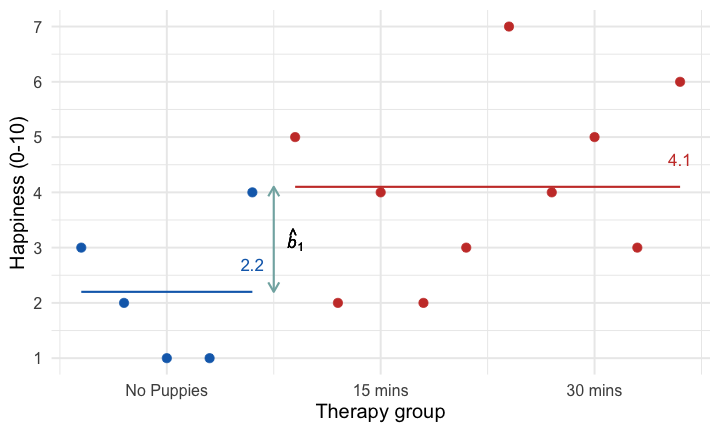<!-- --> .ong[ $$ `\begin{aligned} \hat{b}_1 &= 4.1-2.2 = 1.9 \end{aligned}` $$ ] --- class: center # The contrast model: Contrast 2 <!-- --> --- class: center # The contrast model: Contrast 2 <!-- --> .ong[ $$ `\begin{aligned} \hat{b}_2 &= 5-3.2 = 1.8 \end{aligned}` $$ ] --- # Parameter estimates ```r puppy_vs_none <- c(-2/3, 1/3, 1/3) short_vs_long <- c(0, -1/2, 1/2) contrasts(puppy_tib$dose) <- cbind(puppy_vs_none, short_vs_long) puppy_lm <- lm(happiness ~ dose, data = puppy_tib) broom::tidy(puppy_lm, conf.int = TRUE) ``` <br> .center[ <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> <th style="text-align:right;"> conf.low </th> <th style="text-align:right;"> conf.high </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;"> 3.47 </td> <td style="text-align:right;"> 0.36 </td> <td style="text-align:right;"> 9.57 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 2.68 </td> <td style="text-align:right;"> 4.26 </td> </tr> <tr> <td style="text-align:left;"> dosepuppy_vs_none </td> <td style="text-align:right;background-color: yellow !important;"> 1.90 </td> <td style="text-align:right;"> 0.77 </td> <td style="text-align:right;"> 2.47 </td> <td style="text-align:right;"> 0.03 </td> <td style="text-align:right;"> 0.23 </td> <td style="text-align:right;"> 3.57 </td> </tr> <tr> <td style="text-align:left;"> doseshort_vs_long </td> <td style="text-align:right;background-color: yellow !important;"> 1.80 </td> <td style="text-align:right;"> 0.89 </td> <td style="text-align:right;"> 2.03 </td> <td style="text-align:right;"> 0.07 </td> <td style="text-align:right;"> -0.13 </td> <td style="text-align:right;"> 3.73 </td> </tr> </tbody> </table> ] --- background-image: none background-color: #000000 class: no-scribble <video width="100%" height="100%" controls id="my_video"> <source src="media/milton_insert_snow.mp4" type="video/mp4"> </video> --- # *Post hoc* tests * In the absence of specific hypotheses + Compare all pairs of means to see where the specific differences lie -- * Problem + Inflates the Type I error rate .center[.eq_lrge[.ong[ $$ `\begin{aligned} \text{Familywise error} = 1-0.95^n \end{aligned}` $$ ]]] -- * Solution + Adjust the alpha (or test statistic) to be more conservative .center[.eq_lrge[.ong[ $$ `\begin{aligned} \text{Bonferroni} \ \alpha = \frac{\alpha}{\text{number of tests}} \end{aligned}` $$ ]]] --- # *Post hoc* tests ```r modelbased::estimate_contrasts(puppy_lm, adjust = "bonferroni") ``` <br> <table> <thead> <tr> <th style="text-align:left;"> Level1 </th> <th style="text-align:left;"> Level2 </th> <th style="text-align:right;"> Difference </th> <th style="text-align:right;"> CI_low </th> <th style="text-align:right;"> CI_high </th> <th style="text-align:right;"> SE </th> <th style="text-align:right;"> df </th> <th style="text-align:right;"> t </th> <th style="text-align:right;"> p </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> 15 mins </td> <td style="text-align:left;"> 30 mins </td> <td style="text-align:right;"> -1.8 </td> <td style="text-align:right;"> -4.27 </td> <td style="text-align:right;"> 0.67 </td> <td style="text-align:right;"> 0.89 </td> <td style="text-align:right;"> 12 </td> <td style="text-align:right;"> -2.03 </td> <td style="text-align:right;"> 0.20 </td> </tr> <tr> <td style="text-align:left;"> No puppies </td> <td style="text-align:left;"> 15 mins </td> <td style="text-align:right;"> -1.0 </td> <td style="text-align:right;"> -3.47 </td> <td style="text-align:right;"> 1.47 </td> <td style="text-align:right;"> 0.89 </td> <td style="text-align:right;"> 12 </td> <td style="text-align:right;"> -1.13 </td> <td style="text-align:right;"> 0.84 </td> </tr> <tr> <td style="text-align:left;"> No puppies </td> <td style="text-align:left;"> 30 mins </td> <td style="text-align:right;"> -2.8 </td> <td style="text-align:right;"> -5.27 </td> <td style="text-align:right;"> -0.33 </td> <td style="text-align:right;"> 0.89 </td> <td style="text-align:right;"> 12 </td> <td style="text-align:right;"> -3.16 </td> <td style="text-align:right;"> 0.02 </td> </tr> </tbody> </table> --- # Trend analysis (Polynomial contrasts) .pull-left[ * Test for trends in the means * Makes sense only for ordered groups ```r contrasts(puppy_tib$dose) <- contr.poly(3) puppy_trend <- lm(happiness ~ dose, data = puppy_tib) broom::tidy(puppy_trend, conf.int = TRUE) ``` <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> <th style="text-align:right;"> conf.low </th> <th style="text-align:right;"> conf.high </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> (Intercept) </td> <td style="text-align:right;"> 3.467 </td> <td style="text-align:right;"> 0.362 </td> <td style="text-align:right;"> 9.574 </td> <td style="text-align:right;"> 0.000 </td> <td style="text-align:right;"> 2.678 </td> <td style="text-align:right;"> 4.256 </td> </tr> <tr> <td style="text-align:left;"> dose.L </td> <td style="text-align:right;"> 1.980 </td> <td style="text-align:right;"> 0.627 </td> <td style="text-align:right;"> 3.157 </td> <td style="text-align:right;"> 0.008 </td> <td style="text-align:right;"> 0.613 </td> <td style="text-align:right;"> 3.346 </td> </tr> <tr> <td style="text-align:left;"> dose.Q </td> <td style="text-align:right;"> 0.327 </td> <td style="text-align:right;"> 0.627 </td> <td style="text-align:right;"> 0.521 </td> <td style="text-align:right;"> 0.612 </td> <td style="text-align:right;"> -1.040 </td> <td style="text-align:right;"> 1.693 </td> </tr> </tbody> </table> ] .pull-right[ <!-- --> ] --- background-image: url("media/andy_kissing_milton_20180831_processed.jpg") background-size: cover # Summary -- .whitebox[ * Categorical predictors can be coded to test specific a priori hypotheses * First devise contrasts to test your hypotheses + Independent + *K*-1 contrasts + Each compares 2 'chunks' * Assign ‘weights’ to each group within each contrast + Assign 1 chunk positive values and the other negative + Assign an initial weight equal to the number of conditions in the opposite chunk + Divide the initial weight by the number of groups with non-zero weights * *Post hoc* tests + Compare all pairs of group means but adjusting for multiple tests * Polynomial contrasts (trend analysis) + Test for trends in the means of ordered categories ]