Multilevel models
University of Sussex





|
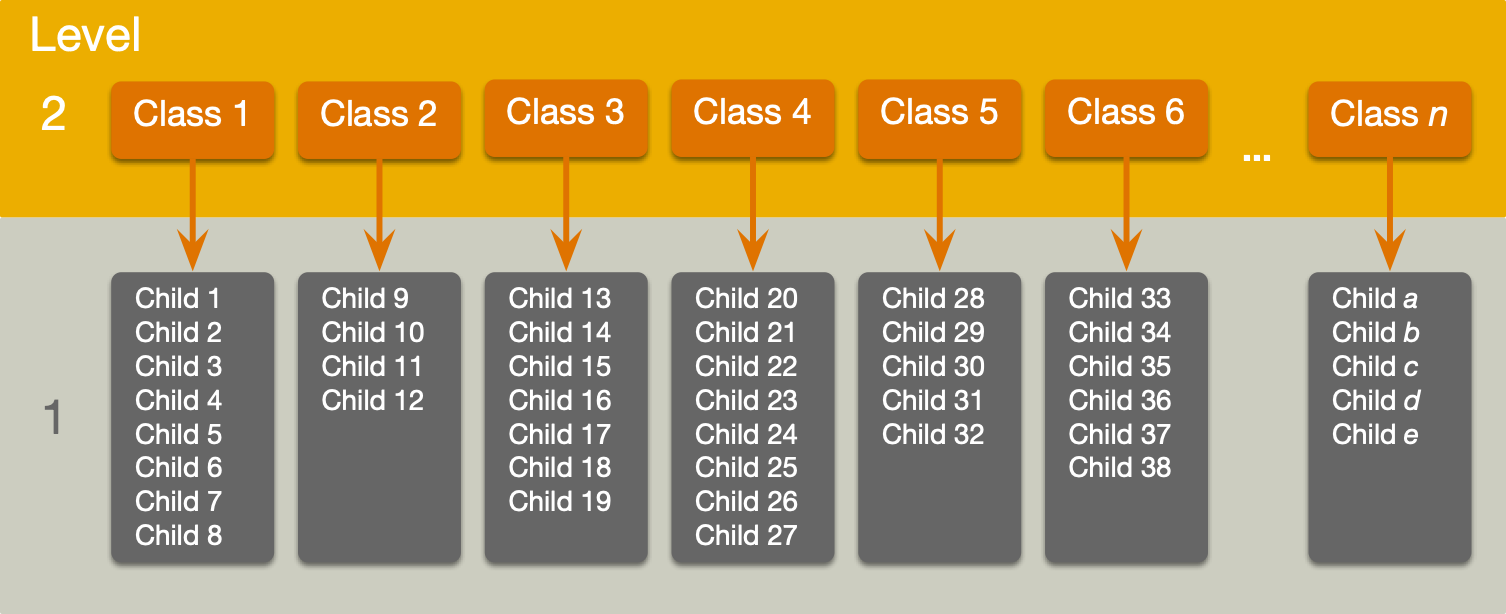
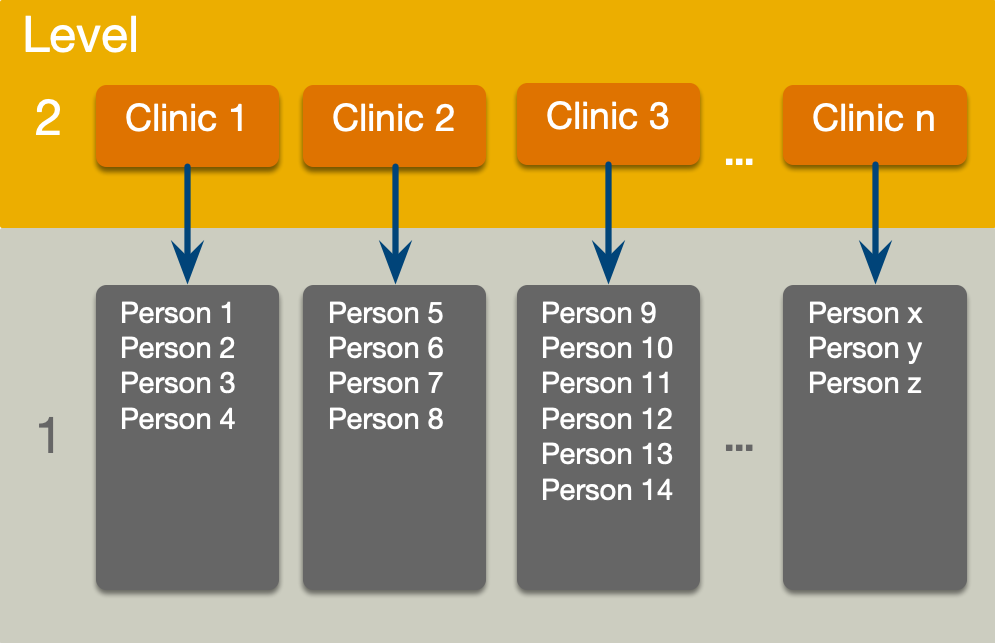
A two-level hierarchy
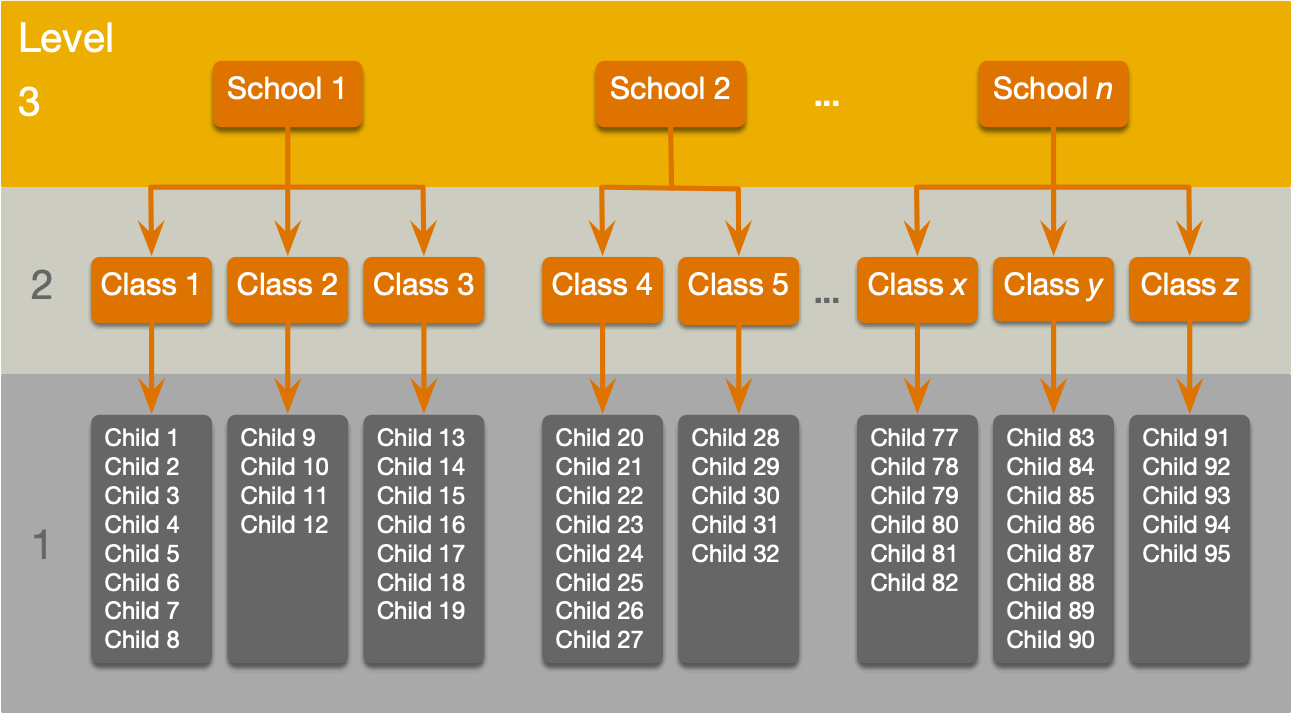
A three-level hierarchy


The surgery data hierarchy
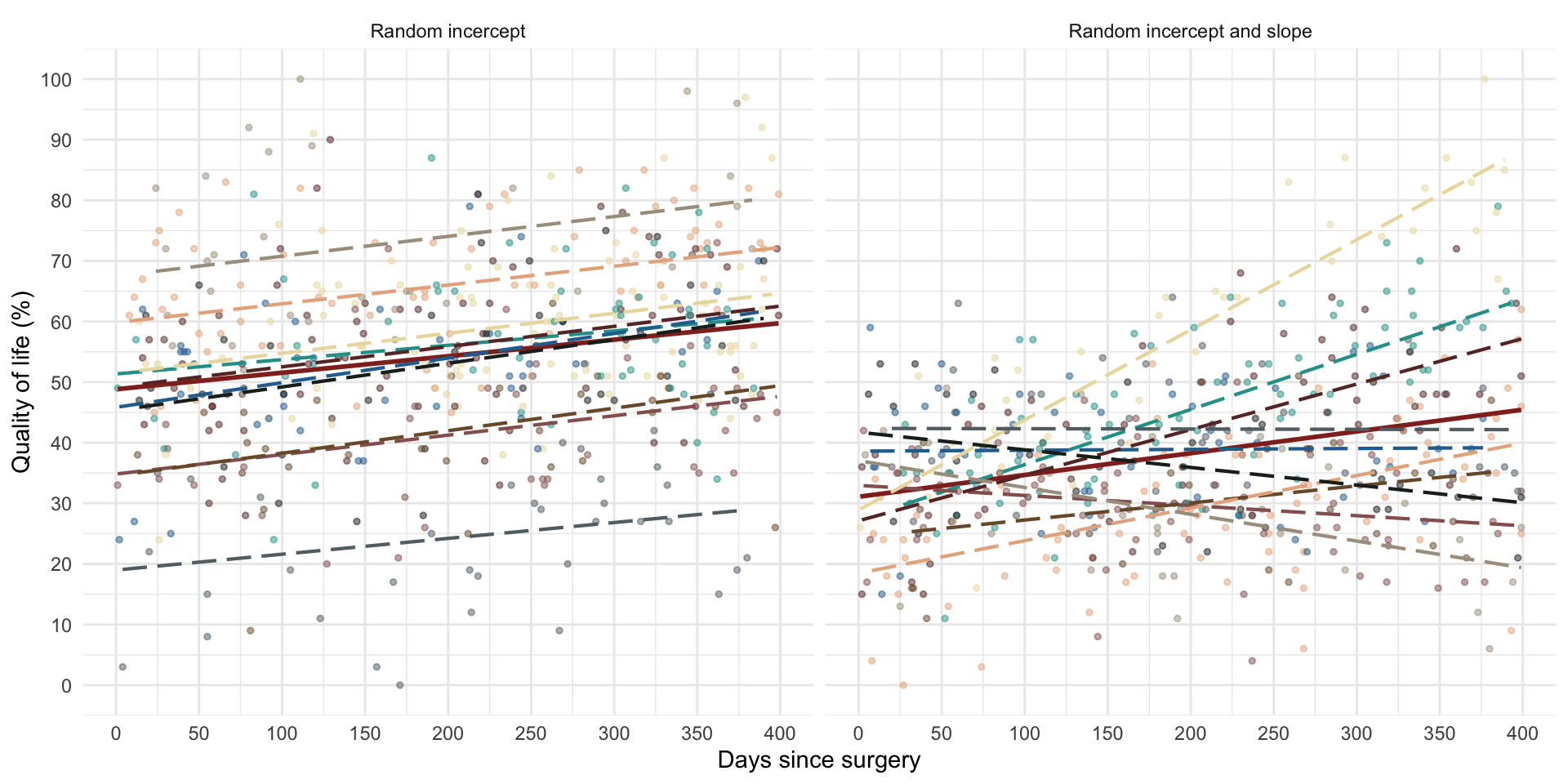
Random intercept
\[ \begin{aligned} \text{QoL}_{ij} &= [\beta_0 + \beta_1\text{Days}_{ij}] + [u_{0j} + \varepsilon_{ij}] \\ \end{aligned} \]
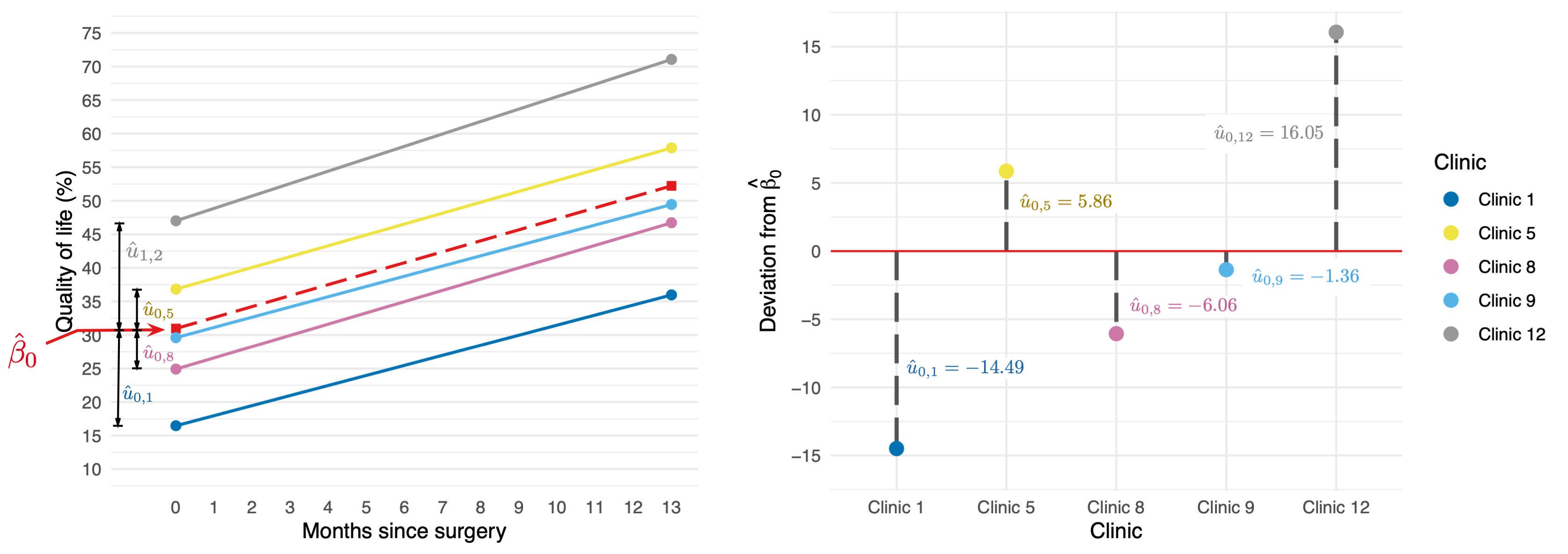
\[ \begin{aligned} u_0 \sim N(0, \sigma^2_{u_0}) \end{aligned} \]
Random slope
\[ \begin{aligned} \text{QoL}_{ij} &= [\beta_0 + \beta_1\text{Days}_{ij}] + [u_{0j} + u_{1j}\text{Days}_{ij} + \varepsilon_{ij}] \\ \end{aligned} \]
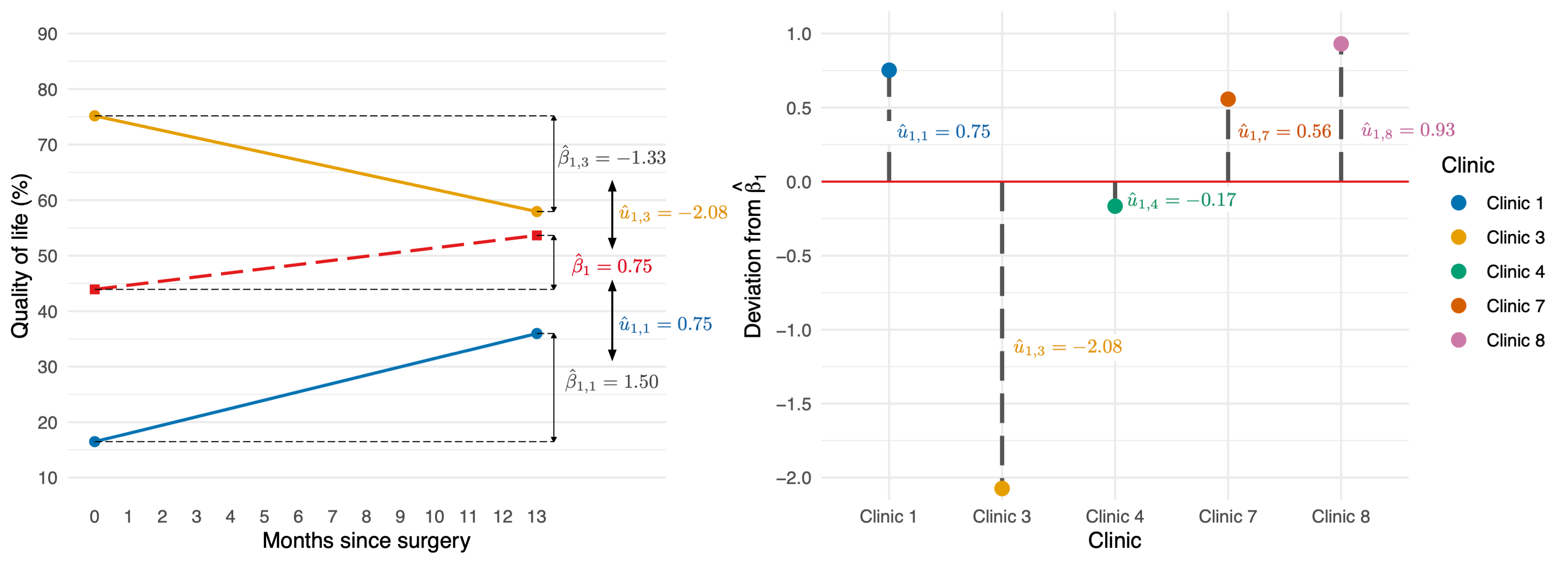
\[ \begin{aligned} u_1 \sim N(0, \sigma^2_{u_1}) \end{aligned} \]
Level 1 errors

Visualise the data
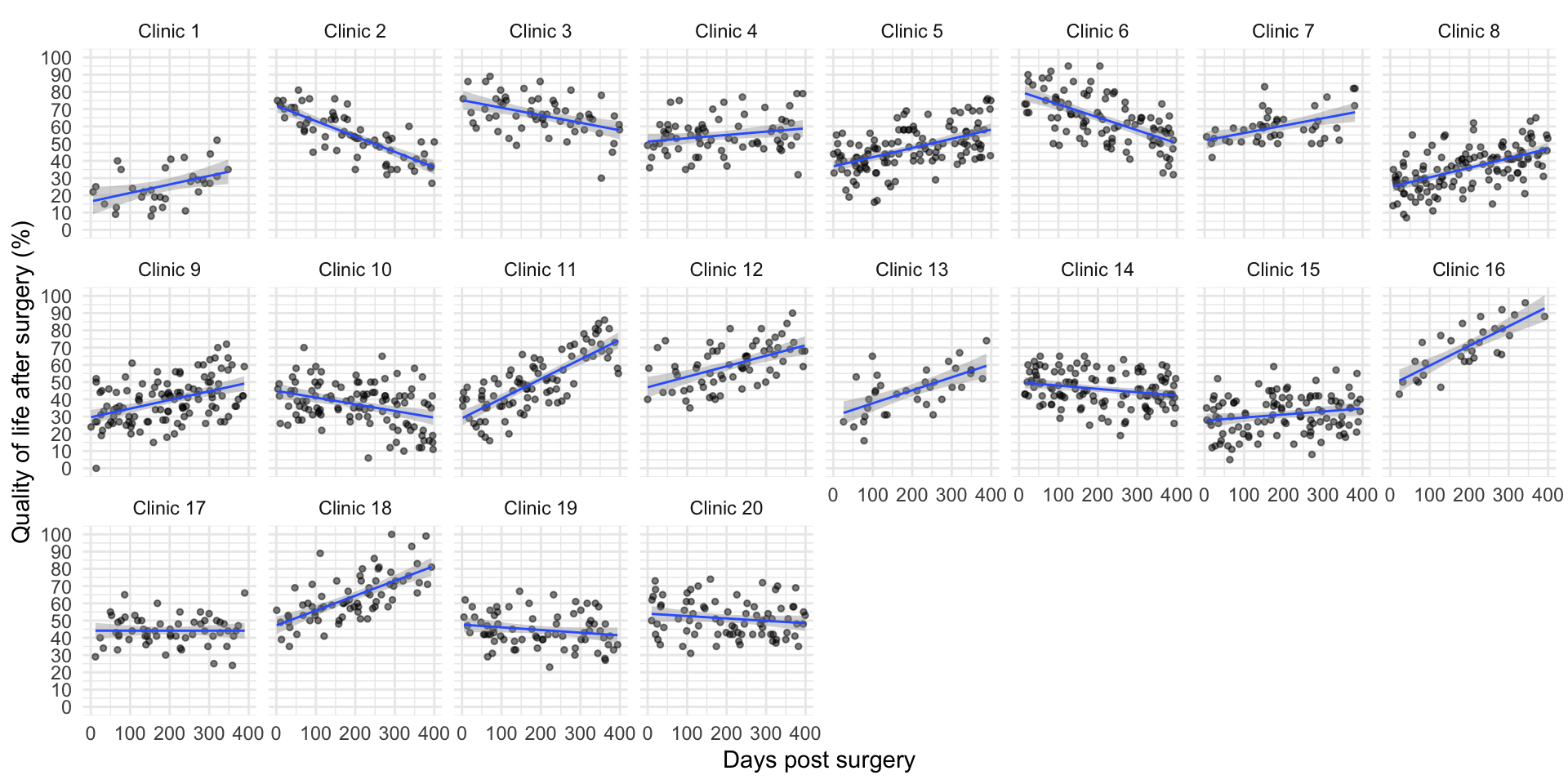
Fitting fixed-effect models within clinics
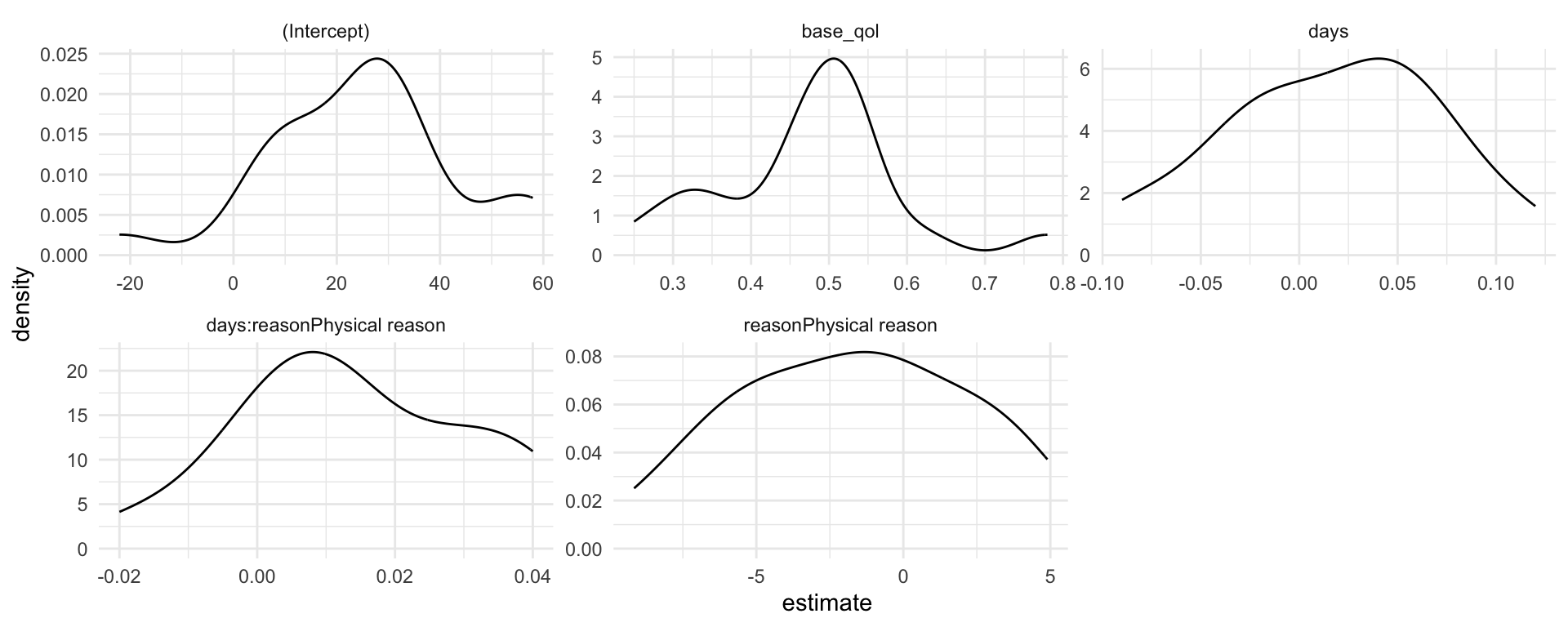
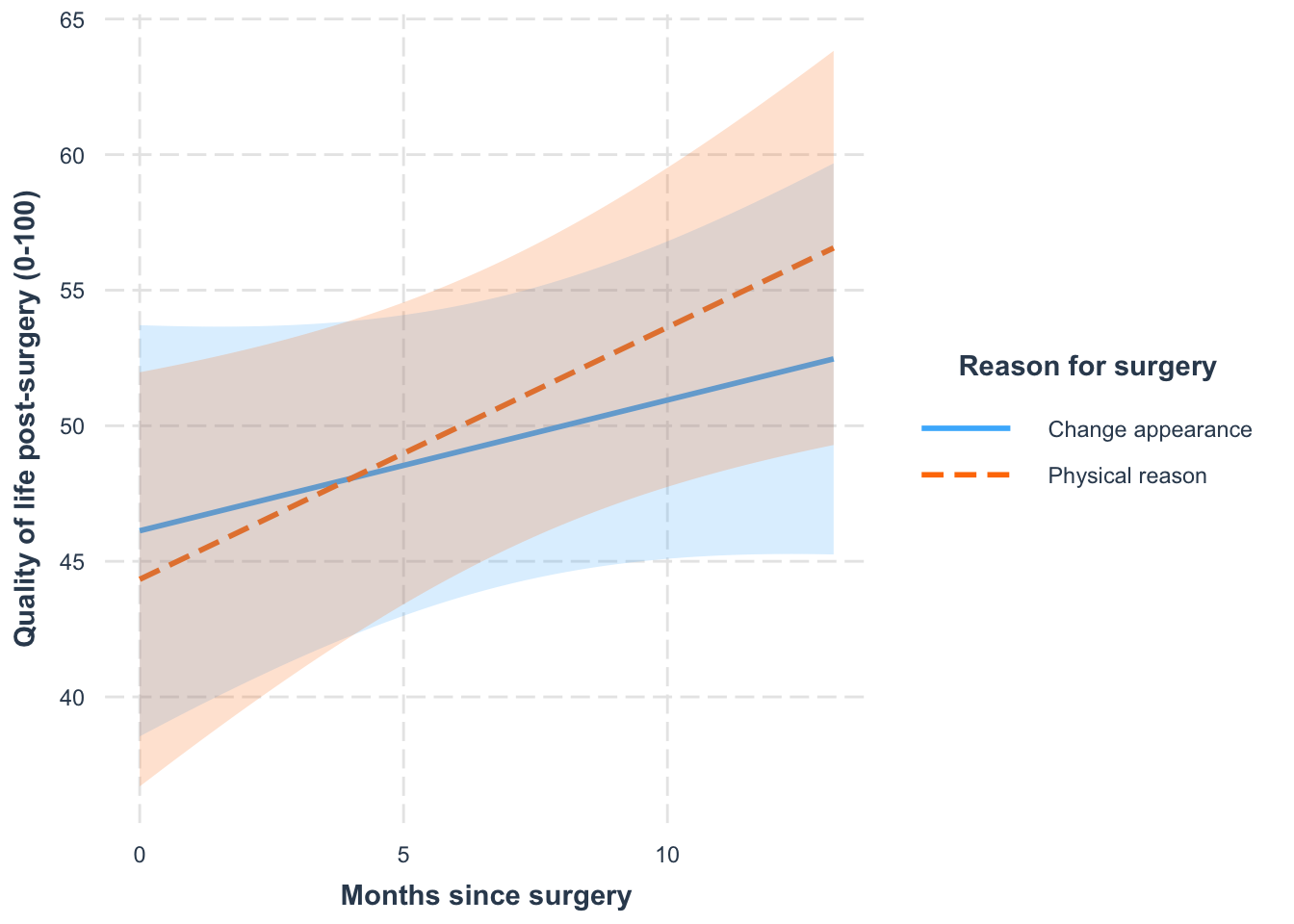
Simple slopes
| reason | Coefficient | SE | CI | CI_low | CI_high | t | df_error | p |
|---|---|---|---|---|---|---|---|---|
| Change appearance | 0.482 | 0.397 | 0.95 | -0.346 | 1.311 | 1.215 | 19.623 | 0.239 |
| Physical reason | 0.930 | 0.401 | 0.95 | 0.094 | 1.765 | 2.316 | 20.558 | 0.031 |
Write-up
- For those who had surgery to change their appearance, their quality of life increased over time but not significantly so, \(\beta\) = 0.48 [−0.35, 1.31], t(19.62) = 1.22, p = 0.239. Quality of life increased by 5.76 units (on the 100-point scale) per year.
- For those who had surgery to help with a physical problem, their quality of life significantly increased over time, \(\beta\) = 0.93 [0.09, 1.77], t(20.56) = 2.32, p = 0.031. Quality of life increased by 11.16 units (on the 100-point scale) per year.