class: center, middle, title-slide, inverse layout: false <audio controls> <source src="media/winterfylleth_a_careworn_heart.mp3" type="audio/mpeg"> <source src="media/winterfylleth_a_careworn_heart.ogg" type="audio/ogg"/> </audio> # Beyond significance tests ## Professor Andy Field <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/twitter_60.png"> <span style="line-height:40px;">@profandyfield</span> </div> <div> <img style="vertical-align:middle; width:60px" src="media/youtube.png"> <span style="line-height:40px;">www.youtube.com/user/ProfAndyField/</span> </div> <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/ds_com_fav.png"> <span style="line-height:40px;">www.discoveringstatistics.com</span> </div> <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/milton_grey_fav.png"> <span style="line-height:40px;">www.milton-the-cat.rocks</span> </div> <div> <img style="vertical-align:middle; width:30px; height:30px" src="media/discovr_fav.png"> <span style="line-height:40px;">www.discovr.rocks</span> </div> ??? Music: Winterfylleth A Careworn Heart h or ?: Toggle the help window j: Jump to next slide k: Jump to previous slide b: Toggle blackout mode m: Toggle mirrored mode. p: Toggle PresenterMode f: Toggle Fullscreen t: Reset presentation timer <number> + <Return>: Jump to slide <number> c: Create a clone presentation on a new window --- class: center 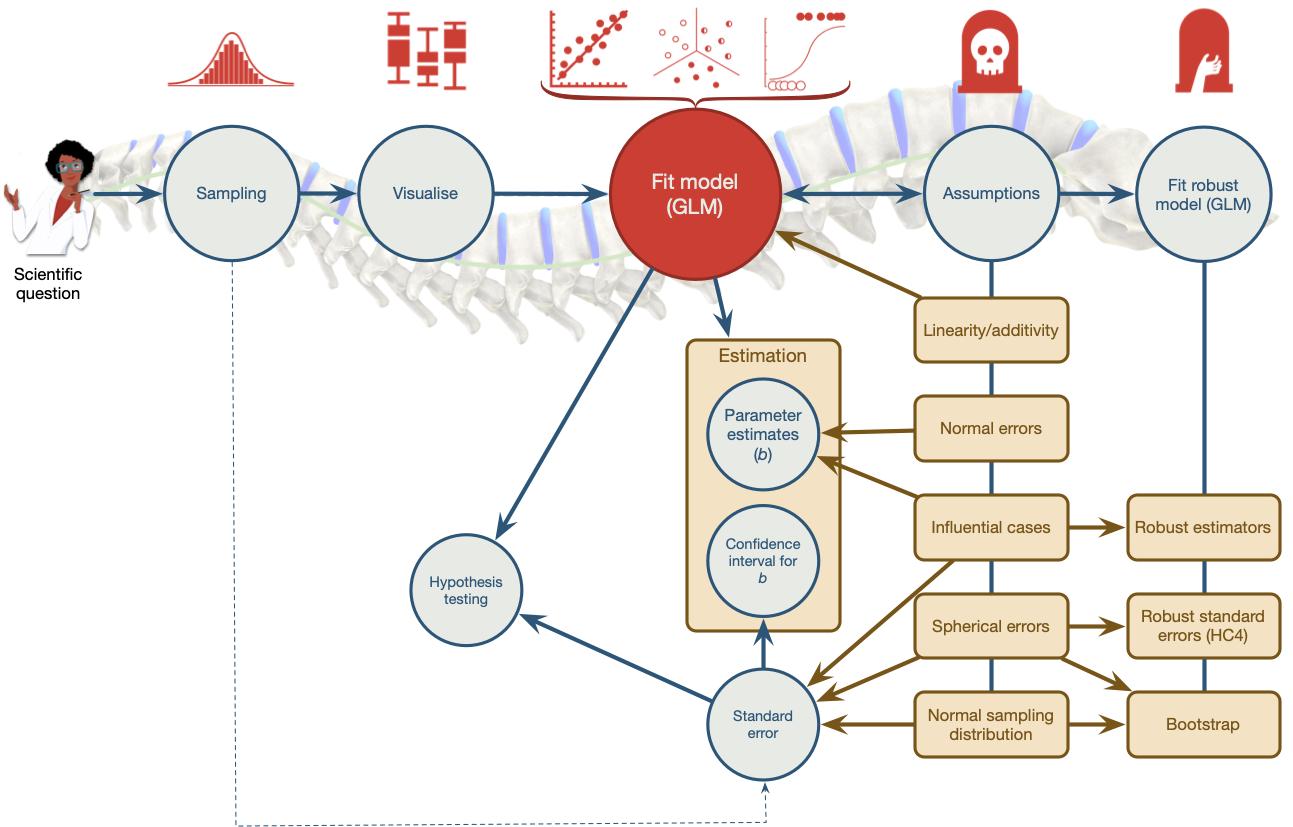 ??? We've seen this map of the process of fitting models before --- class: center 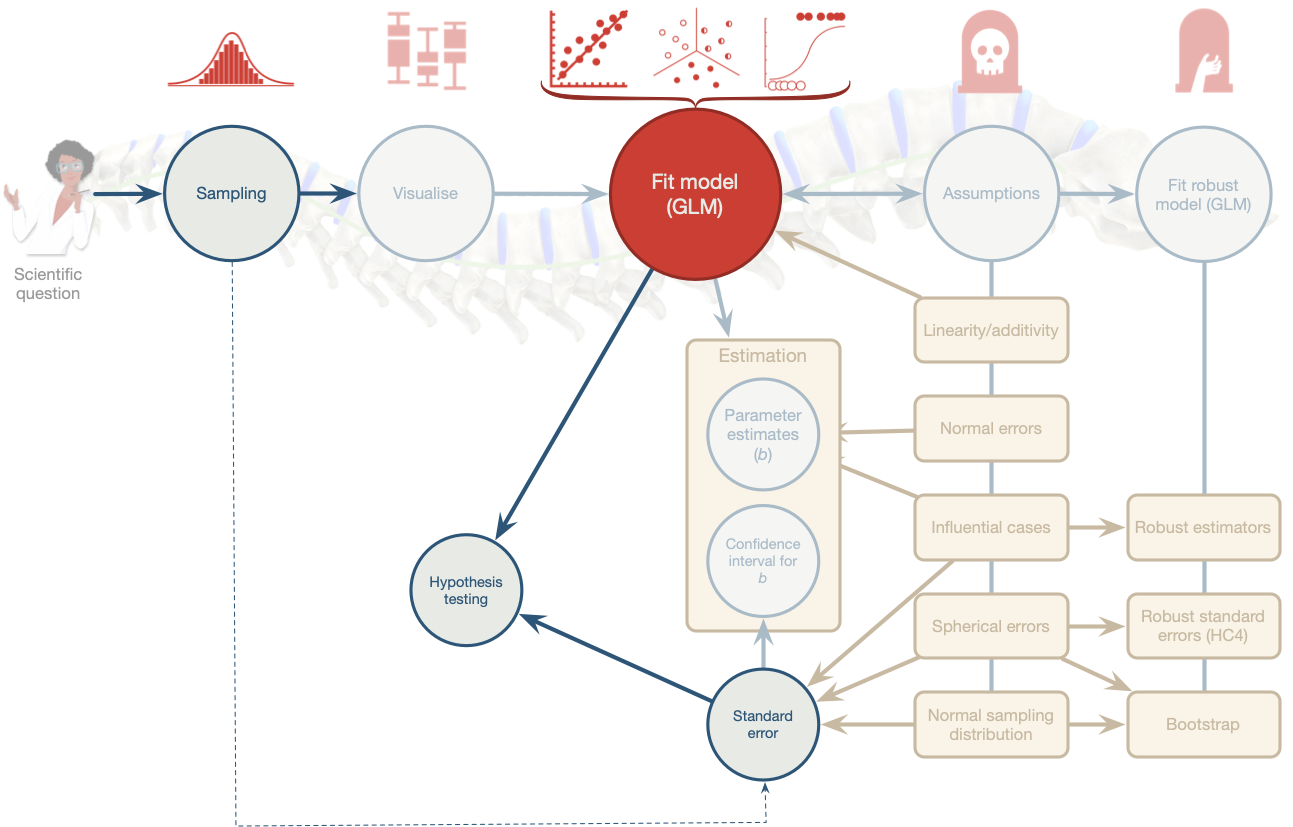 ??? Today we focus on NHST. --- # Learning outcomes Effect sizes * Understand what an effect size is and the relative merits of effect sizes -- Bayes factors * Articulate the principles of Bayesian approaches * Define what a Bayes factor represents --- # Problems with *p* – A recap Tells us nothing about importance because *p* depends upon sample size. -- Provides little evidence about the null (or alternative) hypothesis -- Encourages all-or-nothing thinking -- Based on long-run probabilities * *p* is the frequency of the observed test statistic relative to all test statistics from an infinite number of identical experiments with the exact same a priori sample size. * The type I error rate is in a given study is either 0 or 1, but we don’t know which. --- # Effect sizes Raw effect size, the parameter (*b*) Standardized version of the parameter * `\(\beta\)` * *r* + 0.1 = small, 0.5 = large + Try to avoid these thresholds * Cohen’s *d* + Difference between means divided by standard deviation (pooled or control group) + *d* = 1, the means are 1 standard deviation apart, *d* = 0, the means are the same + 0.2 = small, 0.8 = large + Try to avoid these thresholds --- # Cohen's *d* ## Control group *sd* .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} \hat{d} &= \frac{\bar{X}_\text{Exp}-\bar{X}_\text{Control}}{s_\text{Control}} \\ \end{aligned}` $$ ] ] ] -- ## Pooled *sd* .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} \hat{d} &= \frac{\bar{X}_1-\bar{X}_2}{s_p} \\ s_p &= \sqrt{\frac{(N_1-1)s^2_1 + (N_2-1)s^2_2}{N_1 + N_2 -2}} \end{aligned}` $$ ] ] ] --- class: center .pull-left[ ## Teddy bear therapy  ] .pull-right[ ## Control group  ] --- # Cohen's *d* .center[ <table> <caption>Summary statistics for Study 2</caption> <thead> <tr> <th style="text-align:left;"> group </th> <th style="text-align:right;"> n </th> <th style="text-align:right;"> Mean </th> <th style="text-align:right;"> Standard deviation </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Teddy </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 12.89 </td> <td style="text-align:right;"> 5.63 </td> </tr> <tr> <td style="text-align:left;"> Book </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 7.89 </td> <td style="text-align:right;"> 4.83 </td> </tr> </tbody> </table> ] ## Control group *sd* .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} \hat{d} &= \frac{\bar{X}_\text{Exp}-\bar{X}_\text{Control}}{s_\text{Control}} \\ &= \frac{12.89-7.89}{4.83} \\ &= 1.04 \end{aligned}` $$ ] ] ] --- # Cohen's *d* .center[ <table> <caption>Summary statistics for Study 2</caption> <thead> <tr> <th style="text-align:left;"> group </th> <th style="text-align:right;"> n </th> <th style="text-align:right;"> Mean </th> <th style="text-align:right;"> Standard deviation </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Teddy </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 12.89 </td> <td style="text-align:right;"> 5.63 </td> </tr> <tr> <td style="text-align:left;"> Book </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 7.89 </td> <td style="text-align:right;"> 4.83 </td> </tr> </tbody> </table> ] ## Pooled *sd* .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} s_p &= \sqrt{\frac{(100-1)5.63^2 + (100-1)4.83^2}{100 + 100 -2}} = 5.25 \\ \hat{d} &= \frac{12.89-7.89}{5.25} \\ &= 0.95 \end{aligned}` $$ ] ] ] --- class: centre ## Same effects, different *p*s -- .pull-left[ ### Study 1: *n* = 20 <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 12.89 </td> <td style="text-align:right;background-color: white !important;"> 0.525 </td> <td style="text-align:right;background-color: white !important;"> 24.565 </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 0 </td> </tr> <tr> <td style="text-align:left;"> groupBook </td> <td style="text-align:right;background-color: yellow !important;"> -5.00 </td> <td style="text-align:right;"> 0.742 </td> <td style="text-align:right;"> -6.738 </td> <td style="text-align:right;background-color: yellow !important;"> 0 </td> </tr> </tbody> </table> ] -- .pull-right[ ### Study 2: *n* = 200 <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 12.8 </td> <td style="text-align:right;background-color: white !important;"> 2.054 </td> <td style="text-align:right;background-color: white !important;"> 6.233 </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 0.000 </td> </tr> <tr> <td style="text-align:left;"> groupBook </td> <td style="text-align:right;background-color: yellow !important;"> -5.0 </td> <td style="text-align:right;"> 2.904 </td> <td style="text-align:right;"> -1.722 </td> <td style="text-align:right;background-color: yellow !important;"> 0.102 </td> </tr> </tbody> </table> ] <br> -- ## Zero effect (approx), significant *p* .center[ ### Study 3: *n* = 200,000 <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 12.113 </td> <td style="text-align:right;background-color: white !important;"> 0.018 </td> <td style="text-align:right;background-color: white !important;"> 660.082 </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 0.000 </td> </tr> <tr> <td style="text-align:left;"> groupBook </td> <td style="text-align:right;background-color: yellow !important;"> 0.052 </td> <td style="text-align:right;"> 0.026 </td> <td style="text-align:right;"> 1.997 </td> <td style="text-align:right;background-color: yellow !important;"> 0.046 </td> </tr> </tbody> </table> ] --- class: centre ## Same effects, different *p*s .pull-left[ ### Study 1: *n* = 20, *d* = 0.77 <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 12.89 </td> <td style="text-align:right;background-color: white !important;"> 0.525 </td> <td style="text-align:right;background-color: white !important;"> 24.565 </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 0 </td> </tr> <tr> <td style="text-align:left;"> groupBook </td> <td style="text-align:right;background-color: yellow !important;"> -5.00 </td> <td style="text-align:right;"> 0.742 </td> <td style="text-align:right;"> -6.738 </td> <td style="text-align:right;background-color: yellow !important;"> 0 </td> </tr> </tbody> </table> ] .pull-right[ ### Study 2: *n* = 200, *d* = 0.95 <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 12.8 </td> <td style="text-align:right;background-color: white !important;"> 2.054 </td> <td style="text-align:right;background-color: white !important;"> 6.233 </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 0.000 </td> </tr> <tr> <td style="text-align:left;"> groupBook </td> <td style="text-align:right;background-color: yellow !important;"> -5.0 </td> <td style="text-align:right;"> 2.904 </td> <td style="text-align:right;"> -1.722 </td> <td style="text-align:right;background-color: yellow !important;"> 0.102 </td> </tr> </tbody> </table> ] <br> ## Zero effect (approx), significant *p* .center[ ### Study 3: *n* = 200,000, *d* = -0.01 <table> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;"> (Intercept) </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 12.113 </td> <td style="text-align:right;background-color: white !important;"> 0.018 </td> <td style="text-align:right;background-color: white !important;"> 660.082 </td> <td style="text-align:right;background-color: yellow !important;background-color: white !important;"> 0.000 </td> </tr> <tr> <td style="text-align:left;"> groupBook </td> <td style="text-align:right;background-color: yellow !important;"> 0.052 </td> <td style="text-align:right;"> 0.026 </td> <td style="text-align:right;"> 1.997 </td> <td style="text-align:right;background-color: yellow !important;"> 0.046 </td> </tr> </tbody> </table> ] ??? Significance testing is related to sample size. Bigger samples are said to have the ‘power’ to detect smaller effects. In the extreme case, you can have a difference of zero that is deemed significant. (1) You can get the same effect but different significance values depending on the sample size. (2) You can have ‘no effect’ but find it significant if you’re sample is big enough. --- # All or nothing thinking .center[ 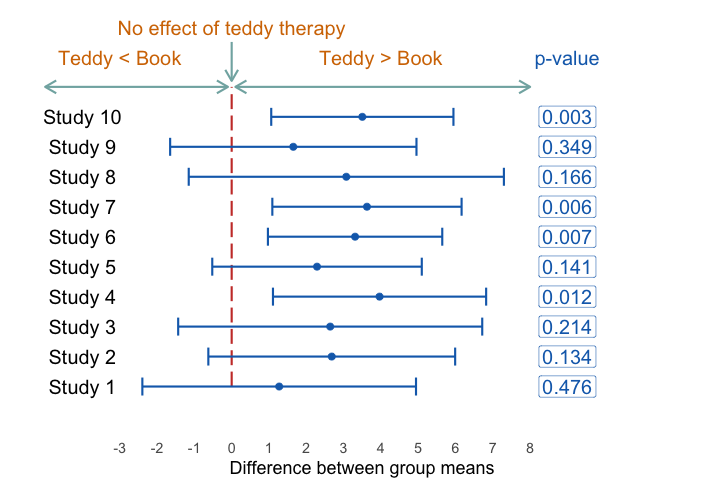<!-- --> ] --- # All or nothing thinking .center[ 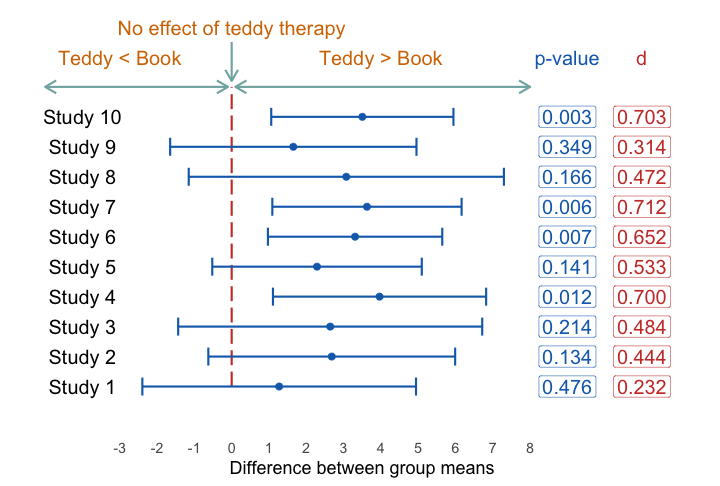<!-- --> ] ??? When we look at effect sizes for our 10 teddy bear studies, we see consistency (unlike with p.) --- .pull-left[ # Effect sizes and *p* * Wetzels et al. (2011). Statistical Evidence in Experimental Psychology: An Empirical Comparison Using 855 *t*-tests. *Perspectives on Psychological Science*, 6, 291–298. [https://doi.org/10.1177/1745691611406923](https://doi.org/10.1177/1745691611406923) ] .pull-right[  ] ??? Based on 885 t-tests from the psychology literature, Wetzels et al looked at the relationship between p, ES and Bayes Factors Ps and ES don’t seem to correspond. For p > .05 (far right column) Ess range from very small to pretty large! Even p < .05, the Ess range from small to large. --- class: center  --- background-image: none background-color: #000000 <video width="100%" height="100%" controls id="my_video"> <source src="media/miltons_walks_01.mp4" type="video/mp4"> </video> --- background-image: none background-color: #000000 <video width="100%" height="100%" controls id="my_video"> <source src="media/miltons_walks_02.mp4" type="video/mp4"> </video> --- class: center  --- # Bayes theorem .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} p(\text{A}|\text{B}) &= \frac{p(\text{B}|\text{A})\times p(\text{A})}{p(\text{B})} \end{aligned}` $$ ] ] ] <br> -- .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} p(\text{model}|\text{data}) &= \frac{p(\text{data}|\text{model})\times p(\text{model})}{p(\text{data})} \end{aligned}` $$ ] ] ] <br> -- .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} \text{posterior probability} &= \frac{\text{liklihood}\times \text{prior probability}}{\text{marginal liklihood}} \end{aligned}` $$ ] ] ] --- .pull-left[  ] .pull-right[ <br> <br> ### Null hypothesis: You’re human ] ??? As you’re probably aware, a significant proportion of people are scaly green lizard aliens disguised as humans. They live happily and peacefully among us causing no harm to anyone, and contributing lots to society by educating humans through things like statistics textbooks. I’ve said too much. The way the world is going right now, it’s only a matter of time before people start becoming intolerant of the helpful alien lizards and try to eject them from their countries. Imagine you have been accused of being a green lizard alien. The government has a hypothesis that you are an alien. They sample your DNA and compare it to an alien DNA sample that they have. It turns out that your DNA matches the alien DNA. --- .pull-left[  ] .pull-right[ <br> <br> ### Null hypothesis: You’re human <br> <br> ### Alt hypothesis: You’re alien! ] --- background-image: none background-color: #000000 <video width="100%" height="100%" controls id="my_video"> <source src="media/miltons_walks_03.mp4" type="video/mp4"> </video> --- background-image: none background-color: #000000 <video width="100%" height="100%" controls id="my_video"> <source src="media/miltons_walks_04.mp4" type="video/mp4"> </video> --- background-image: none background-color: #000000 <video width="100%" height="100%" controls id="my_video"> <source src="media/miltons_walks_05.mp4" type="video/mp4"> </video> --- class: center  -- .ong[ .eq_lrge[ $$ `\begin{aligned} p(\text{hypothesis}|\text{match}) &= \frac{p(\text{match}|\text{hypothesis})\times p(\text{hypothesis})}{p(\text{match})} \end{aligned}` $$ ] ] <br> -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{posterior probability} &= \frac{\text{liklihood}\times \text{prior probability}}{\text{marginal liklihood}} \end{aligned}` $$ ] ] ??? Table 1.2 illustrates your predicament. To keep things simple, imagine that you live on a small island of 2000 inhabitants. One of those people (but not you) is an alien, and his or her DNA will match that of an alien. It is not possible to be an alien and for your DNA not to match, so that cell of the table contains a zero. Now, the remaining 1999 people are not aliens and the majority (1900) have DNA that does not match that of the alien sample that the government has; however, a small number do (99), including you. The posterior probability is our belief in a hypothesis (or parameter, but more on that later) after we have considered the data (hence it is posterior to considering the data). In the alien example, it is our belief that a person is alien (H1) or human (H0) given that their DNA matches alien DNA, p(hypothesis|match). This is the value that we are interested in finding out: the probability of our hypothesis given the data. To calculate this, we need to know the likelihood, the prior probability, and the marginal liklihood. Let’s look at the alternative hypothesis first – that you’re an alien. --- class: center  -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{prior probability} = p(\text{alien}) = \frac{1}{2000} = 0.0005 \end{aligned}` $$ ] ] -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{marginal liklihood} = p(\text{match}) = \frac{100}{2000} = 0.05 \end{aligned}` $$ ] ] -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{liklihood} = p(\text{match}|\text{alien}) = \frac{p(\text{alien} \cap \text{match})}{p(\text{alien})} = \frac{\frac{1}{2000}}{\frac{1}{2000}} = 1 \end{aligned}` $$ ] ] ??? Let The prior probability is our belief in a hypothesis (or parameter) before considering the data. In our alien example, it is the government’s belief in your guilt before they consider whether your DNA matches or not. This would be the base rate for aliens, p(aliens), which in our example is 1 in 2000, or 0.0005. The marginal likelihood, or evidence, is the probability of the observed data, which in this example is the probability of matching DNA, p(match). The data show that there were 100 matches in 2000 cases, so this value is 100/2000, or 0.05. The likelihood is the probability that the observed data could be produced given the hypothesis or model being considered. In the alien example, it is, therefore, the probability that you would find that the DNA matched given that someone was in fact an alien, p(match|alien), which we saw before is 1. --- # Alternative hypothesis (you’re alien) <br> .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} p(\text{alien}|\text{match}) &= \frac{p(\text{match}|\text{alien})\times p(\text{alien})}{p(\text{match})} \\ &= \frac{1\times 0.0005}{0.05} \\ &= 0.01 \end{aligned}` $$ ] ] ] ??? There’s a 1% chance that you’re an alien. Now let’s look at the null. --- class: center  -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{prior probability} = p(\text{human}) = \frac{1999}{2000} = 0.9995 \end{aligned}` $$ ] ] -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{marginal liklihood} = p(\text{match}) = \frac{100}{2000} = 0.05 \end{aligned}` $$ ] ] -- .ong[ .eq_lrge[ $$ `\begin{aligned} \text{liklihood} = p(\text{match}|\text{human}) = \frac{p(\text{human} \cap \text{match})}{p(\text{human})} = \frac{\frac{99}{2000}}{\frac{1999}{2000}} = 0.0495 \end{aligned}` $$ ] ] ??? Let The prior probability is our belief in a hypothesis (or parameter) before considering the data. For the null, this would be the base rate for humans, p(humans), which in our example is 1999 in 2000, or 0.9995. The marginal likelihood, or evidence, is the probability of the observed data, which in this example is the probability of matching DNA, p(match). The data show that there were 100 matches in 2000 cases, so this value is 100/2000, or 0.05. The likelihood is the probability that the observed data could be produced given the hypothesis or model being considered. In the alien example, it is, therefore, the probability that you would find that the DNA matched given that someone was in fact an human, p(match|human), which is 0.0495. --- # Null hypothesis (you’re human) <br> .center[ .ong[ .eq_lrge[ $$ `\begin{aligned} p(\text{human}|\text{match}) &= \frac{p(\text{match}|\text{human})\times p(\text{human})}{p(\text{match})} \\ &= \frac{0.0495\times 0.9995}{0.05} \\ &= 0.99 \end{aligned}` $$ ] ] ] ??? There’s a 99% chance that you’re human. --- class: center .ong[ $$ `\begin{aligned} \text{posterior odds} = \frac{p(\text{hypothesis 1}|\text{data})}{p(\text{hypothesis 2}|\text{data})} = \frac{p(\text{alien}|\text{match})}{p(\text{human}|\text{match})} = \frac{0.01}{0.99} = 0.01 \end{aligned}` $$ ] <br> -- .ong[ $$ `\begin{aligned} \frac{p(\text{alternative}|\text{data})}{p(\text{null}|\text{data})} = \frac{\frac{p(\text{data}|\text{alternative})\times p(\text{alternative})}{p({\text{data})}}}{\frac{p(\text{data}|\text{null})\times p(\text{null})}{p({\text{data})}}} = \frac{p(\text{alien}|\text{match})}{p(\text{human}|\text{match})} = \frac{0.01}{0.99} = 0.01 \end{aligned}` $$ ] <br> -- .ong[ .eq_lrge[ $$ `\begin{aligned} \frac{p(\text{alternative}|\text{data})}{p(\text{null}|\text{data})} = \frac{p(\text{data}|\text{alternative})}{p(\text{data}|\text{null})} \times \frac{p(\text{alternative})}{p(\text{null})} \end{aligned}` $$ ] ] --  --  --  ??? The probability of being an alien (given the data) is 0.01 times more likely than the probability that you are to be human (given the data). You can flip this on it’s head by swapping the fraction (or taking the reciprocal), and say that you are 99 times more likely to be human given a DNA match than you are to be alien. This ratio of the probability of one hypothesis given the data, against another is called the posterior odds. We can write this out in full using Bayes theorm for the two hypotheses …. --- class: center .ong[ .eq_lrge[ $$ `\begin{aligned} \frac{p(\text{alien}|\text{match})}{p(\text{human}|\text{match})} = \frac{p(\text{match}|\text{alien})}{p(\text{match}|\text{human})} \times \frac{p(\text{alien})}{p(\text{human})} \end{aligned}` $$ ] ] --  --  --  <br> <br> <br> <br> <br> .ong[ .eq_lrge[ $$ `\begin{aligned} \frac{0.01}{0.99} &= \frac{1}{0.0495} \times \frac{0.0005}{0.9995} \\ 0.01 &= 20.20 \times 0.0005 \end{aligned}` $$ ] ] -- .tip[ Given a DNA match, we should shift our belief towards that person being an alien by a factor of about 20 ] ??? Our prior belief in you being an alien is 0.0005 (it’s very unlikley). Given your DNA matches, we update our belief – we should shift our belief towards you being an alien by a factor of about 20. --- class: title-slide, inverse # Bayes factor (BF<sub>10</sub>) * The probability of the data given the alternative hypothesis relative to the probability of the data given the null. * The extent to which you should change your beliefs about the alternative hypothesis relative to the null * You sometimes see Bayes factors expressed the opposite way around (BF<sub>01</sub>) <br> -- .center[  ] --- # Bayes factors, *p* and effect sizes<sup>1</sup> .pull-left[  ] -- .pull-right[  ] .footnote[ Wetzels et al. (2011). *Perspectives on Psychological Science*, 6, 291–298. [https://doi.org/10.1177/1745691611406923](https://doi.org/10.1177/1745691611406923) ] ??? Based on 885 t-tests from the psychology literature, Wetzels et al looked at the relationship between p, ES and Bayes Factors Ps and ES don’t seem to correspond. For p > .05 (far right column) Ess range from very small to pretty large! Even p < .05, the Ess range from small to large. --- # Summary * We can go beyond *p* to evaluate the plausibility of a hypothesis * Other methods address more useful questions, are less dependent on sample sizes, and avoid all-or-nothing thinking * Effect sizes quantify the size of the effect * Encourage thinking about effects on a continuum * Bayes factors quantify the relative probability of the data given the null and alternative hypothesis